Test-Time Canonicalization by Foundation Models for Robust Perception
{kind=link}
Abstract
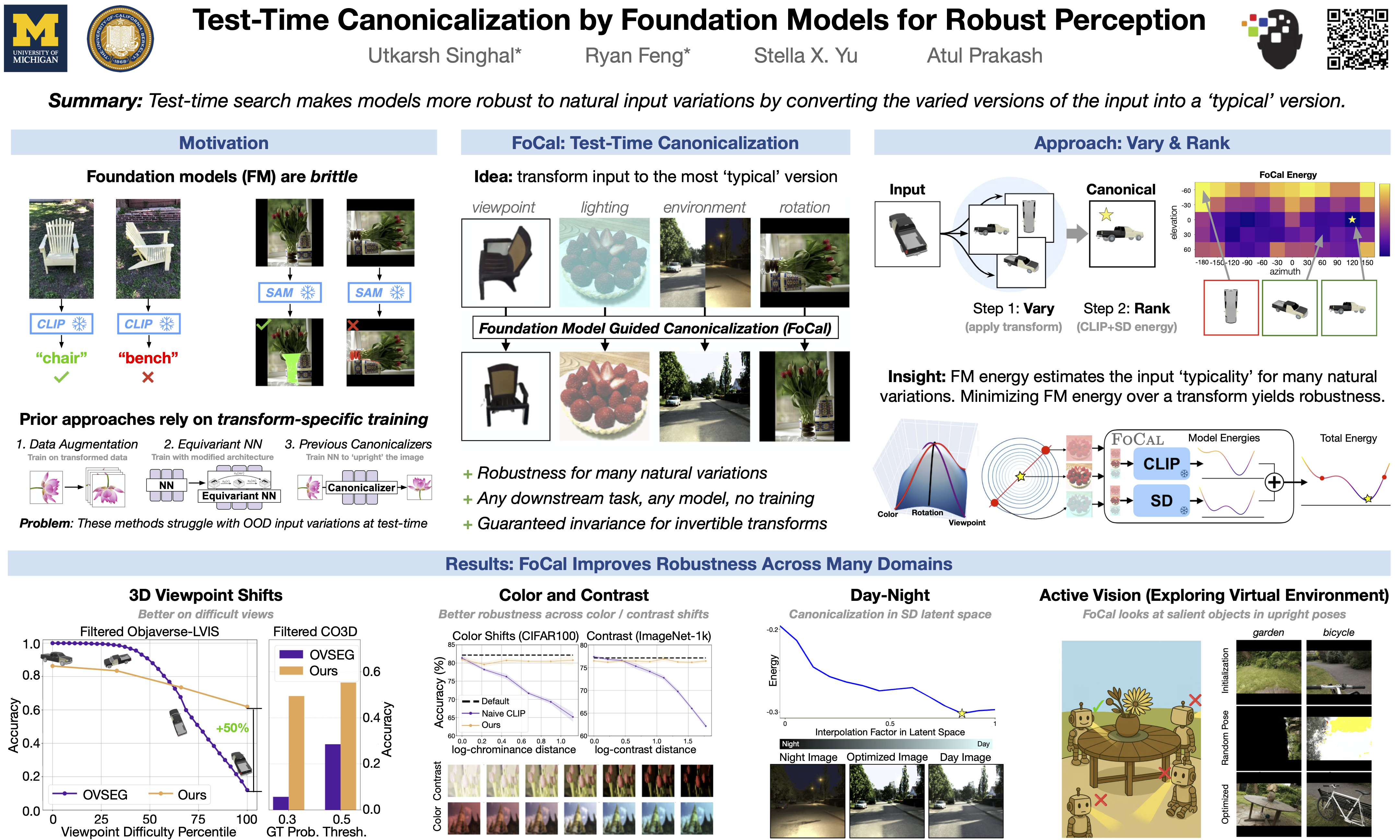
Real-world visual perception requires invariance to diverse transformations, yet current methods rely heavily on specialized architectures or training on predefined augmentations, limiting generalization. We propose FoCal, a test-time, data-driven framework that achieves robust perception by leveraging internet-scale visual priors from foundation models. By generating and optimizing candidate transformations toward visually typical, "canonical" views, FoCal enhances robustness without retraining or architectural changes. Experiments demonstrate improved robustness of CLIP and SAM across challenging transformations, including 2D/3D rotations, illumination shifts (contrast and color), and day-night variations. We also highlight potential applications in active vision. Our approach challenges the assumption that transform-specific training is necessary, instead offering a scalable path to invariance. Our code is available at: https://github.com/sutkarsh/focal.
Lay Summary
Current AI vision systems struggle with everyday transformations that humans handle effortlessly. Show a robot an upside-down chair or a strangely lit room, and it might fail completely. That's because these systems are trained on near-perfect internet photos, not the messy reality they encounter in the real world. Re-training the entire system with each new messy example would be expensive and impractical.The key insight: AI models trained on billions of internet images already know what objects typically look like. We tap into this knowledge by testing different versions of an image (rotating it, adjusting lighting, changing viewpoints) and picking the one that big models like CLIP and Stable Diffusion find most familiar. It's like how you'd mentally rotate an upside-down photo to understand it.This method works remarkably well, even for complex real-world transformations that have been very challenging for previous approaches (like viewpoint changes, day-night changes, and more). As a bonus, FoCal doesn't require re-training and works with any existing vision system. Our work is a step towards making vision systems reliable in real-world conditions, crucial for applications like home robots and self-driving cars.