Randomized Dimensionality Reduction for Euclidean Maximization and Diversity Measures
Jie Gao ⋅ Rajesh Jayaram ⋅ Benedikt Kolbe ⋅ Shay Sapir ⋅ Chris Schwiegelshohn ⋅ Sandeep Silwal ⋅ Erik Waingarten
2025 Poster
{kind=link}
Abstract
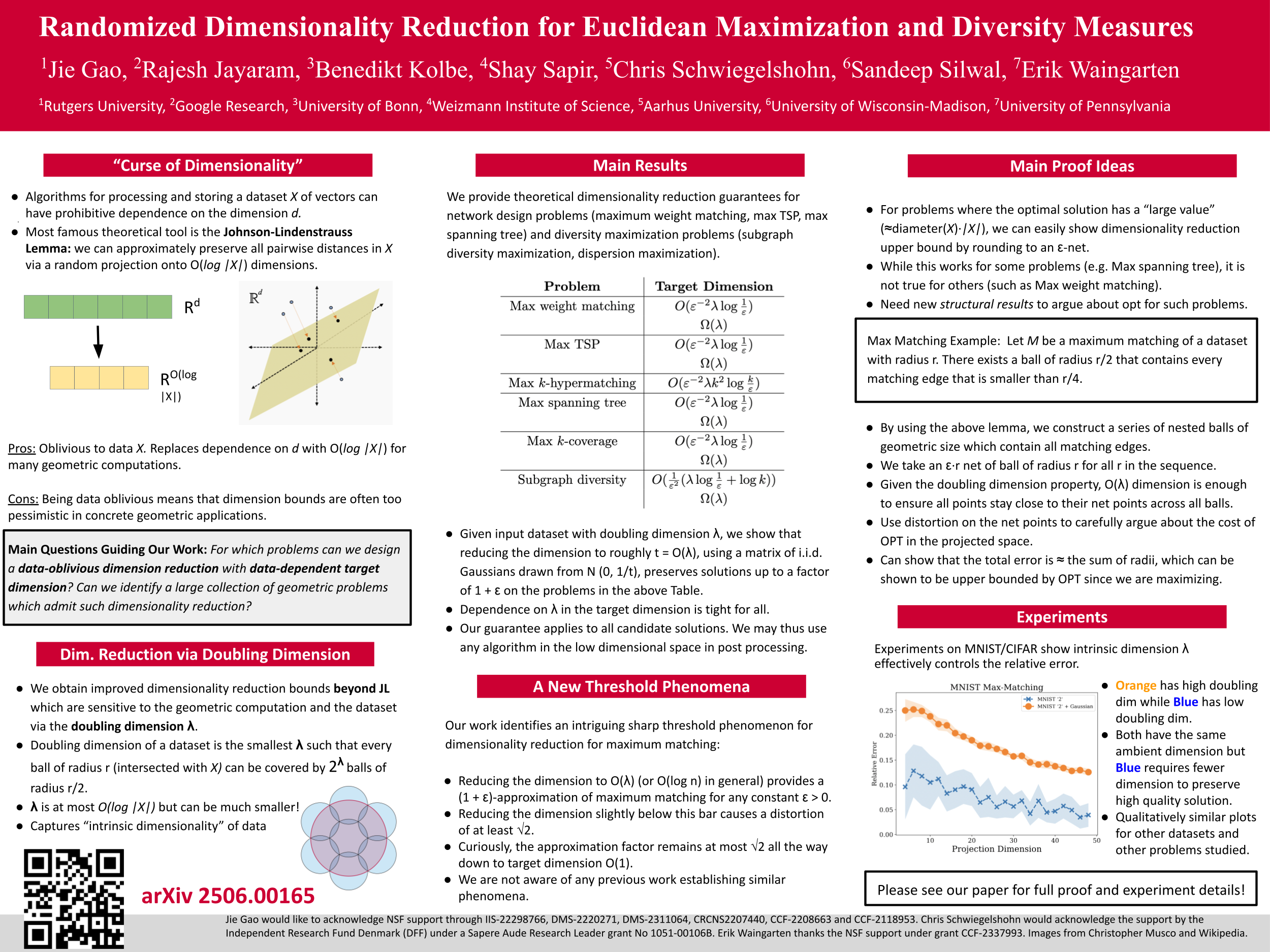
Randomized dimensionality reduction is a widely-used algorithmic technique for speeding up large-scale Euclidean optimization problems. In this paper, we study dimension reduction for a variety of maximization problems, including max-matching, max-spanning tree, as well as various measures for dataset diversity. For these problems, we show that the effect of dimension reduction is intimately tied to the *doubling dimension* $\lambda_X$ of the underlying dataset $X$---a quantity measuring intrinsic dimensionality of point sets. Specifically, the dimension required is $O(\lambda_X)$, which we also show is necessary for some of these problems. This is in contrast to classical dimension reduction results, whose dependence grow with the dataset size $|X|$. We also provide empirical results validating the quality of solutions found in the projected space, as well as speedups due to dimensionality reduction.
Lay Summary
The large sizes of vectors, measured in terms of the number of coordinates they have, creates significant computational bottlenecks in many post processing of these vectors. We study how to significantly reduce the number of coordinates (compression) of vectors without affecting downstream performance for a wide class of problems. We show that the amount of compression possible is mathematically tied to the intrinsic complexity of the input dataset. After reducing the number of coordinates, many post processing steps are much faster without sacrificing quality.
Video
Chat is not available.
Successful Page Load