Info-Coevolution: An Efficient Framework for Data Model Coevolution
{kind=link}
Abstract
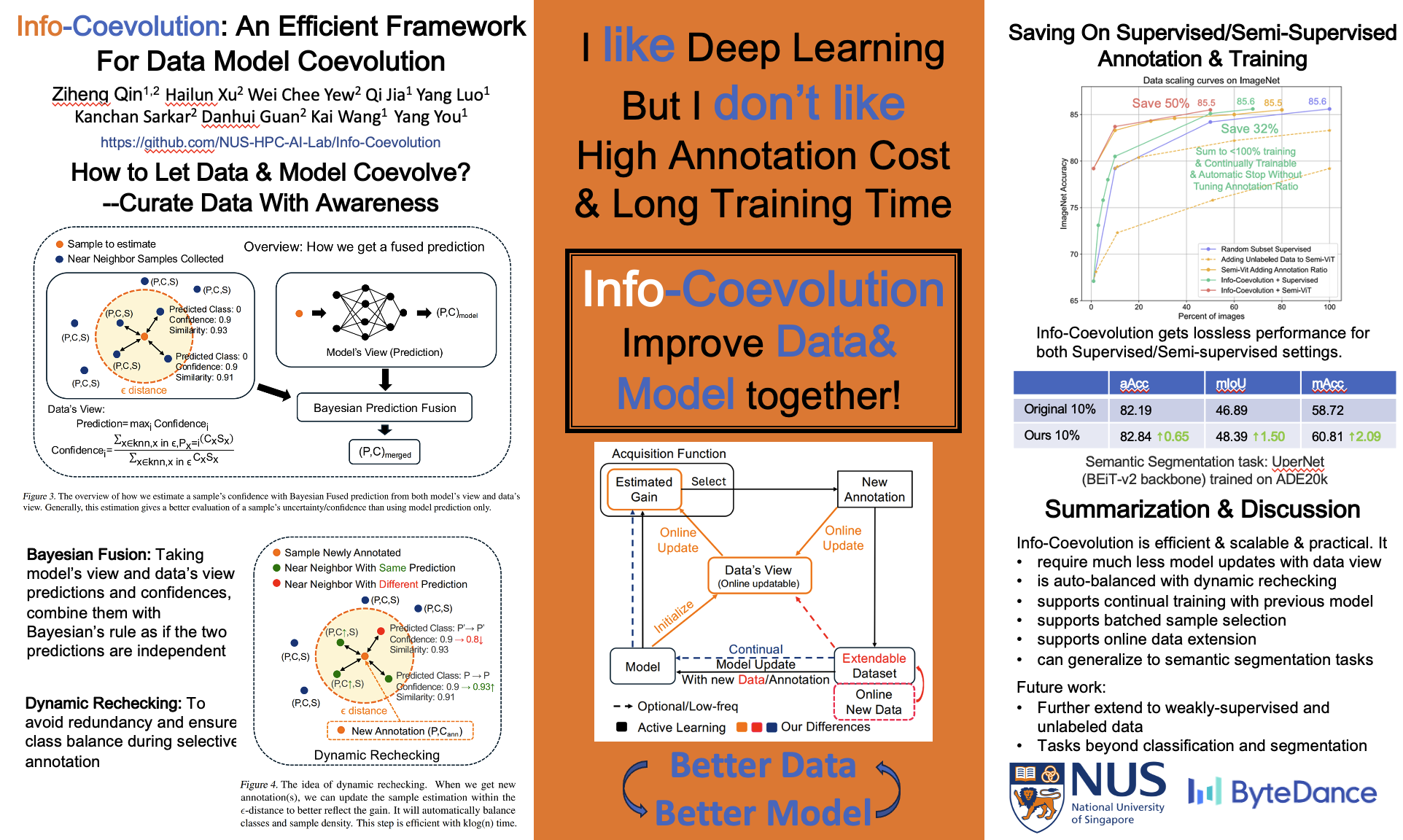
Machine learning relies heavily on data, yet the continuous growth of real-world data poses challenges for efficient dataset construction and training. A fundamental yet unsolved question is: given our current model and data, does a new data (sample/batch) need annotation/learning? Conventional approaches retain all available data, leading to non-optimal data and training efficiency. Active learning aims to reduce data redundancy by selecting a subset of samples to annotate, while it increases pipeline complexity and introduces bias. In this work, we propose Info-Coevolution, a novel framework that efficiently enables models and data to coevolve through online selective annotation with no bias. Leveraging task-specific models (and open-source models), it selectively annotates and integrates online and web data to improve datasets efficiently. For real-world datasets like ImageNet-1K, Info-Coevolution reduces annotation and training costsby 32% without performance loss. It is able to automatically give the saving ratio without tuning the ratio. It can further reduce the annotation ratio to 50% with semi-supervised learning. We also explore retrieval-based dataset enhancement using unlabeled open-source data. Code is available at https://github.com/NUS-HPC-AI-Lab/Info-Coevolution/.
Lay Summary
Machine learning relies on data, and in many cases data (annotation) cost could be higher than the training cost. In this work, we propose an efficient and scalable algorithm, Info-Coevolution, to enable building a dataset at a lower cost. It can save both annotation and training costs, and make the model coevolve with data.