Faster Approximation Algorithms for k-Center via Data Reduction
Arnold Filtser ⋅ Shaofeng Jiang ⋅ Yi Li ⋅ Anurag Murty Naredla ⋅ Ioannis Psarros ⋅ Qiaoyuan Yang ⋅ Qin Zhang
2025 Poster
{kind=link}
Abstract
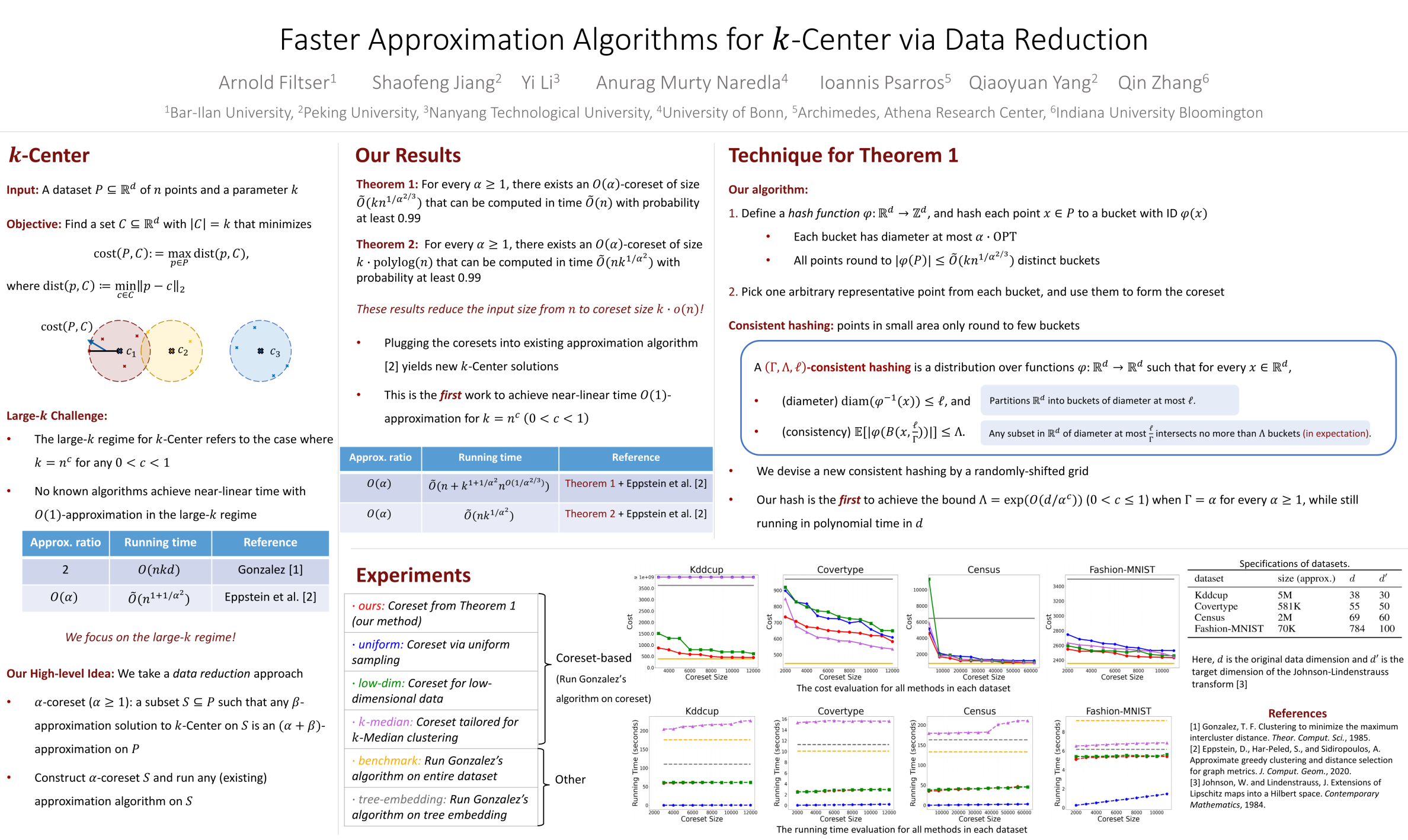
We study efficient algorithms for the Euclidean $k$-Center problem, focusing on the regime of large $k$. We take the approach of data reduction by considering $\alpha$-coreset, which is a small subset $S$ of the dataset $P$ such that any $\beta$-approximation on $S$ is an $(\alpha + \beta)$-approximation on $P$. We give efficient algorithms to construct coresets whose size is $k \cdot o(n)$, which immediately speeds up existing approximation algorithms. Notably, we obtain a near-linear time $O(1)$-approximation when $k = n^c$ for any $0 < c < 1$. We validate the performance of our coresets on real-world datasets with large $k$, and we observe that the coreset speeds up the well-known Gonzalez algorithm by up to $4$ times, while still achieving similar clustering cost. Technically, one of our coreset results is based on a new efficient construction of consistent hashing with competitive parameters. This general tool may be of independent interest for algorithm design in high dimensional Euclidean spaces.
Lay Summary
$k$-Center clustering is a fundamental data clustering problem. In general, this problem aims to find a "best" partition of a dataset into $k$ parts, such that each part has a smallest size (in distance).We aim to devise efficient algorithms for $k$-Center, with a focus on high dimensional data and general parameter $k$, which is a parameter regime relevant to many popular large scale applications. We give the first near-linear time algorithm whose solution is constant factor away from the optimal, for any $k = o(n)$. Our algorithm also demonstrates promising performance on real datasets. Our result is obtained via a novel data reduction method for $k$-Center.This work not only advances the theoretical front of $k$-Center, but also makes impact on the practical side to enable more efficient clustering analysis on high dimensional big data.
Video
Chat is not available.
Successful Page Load