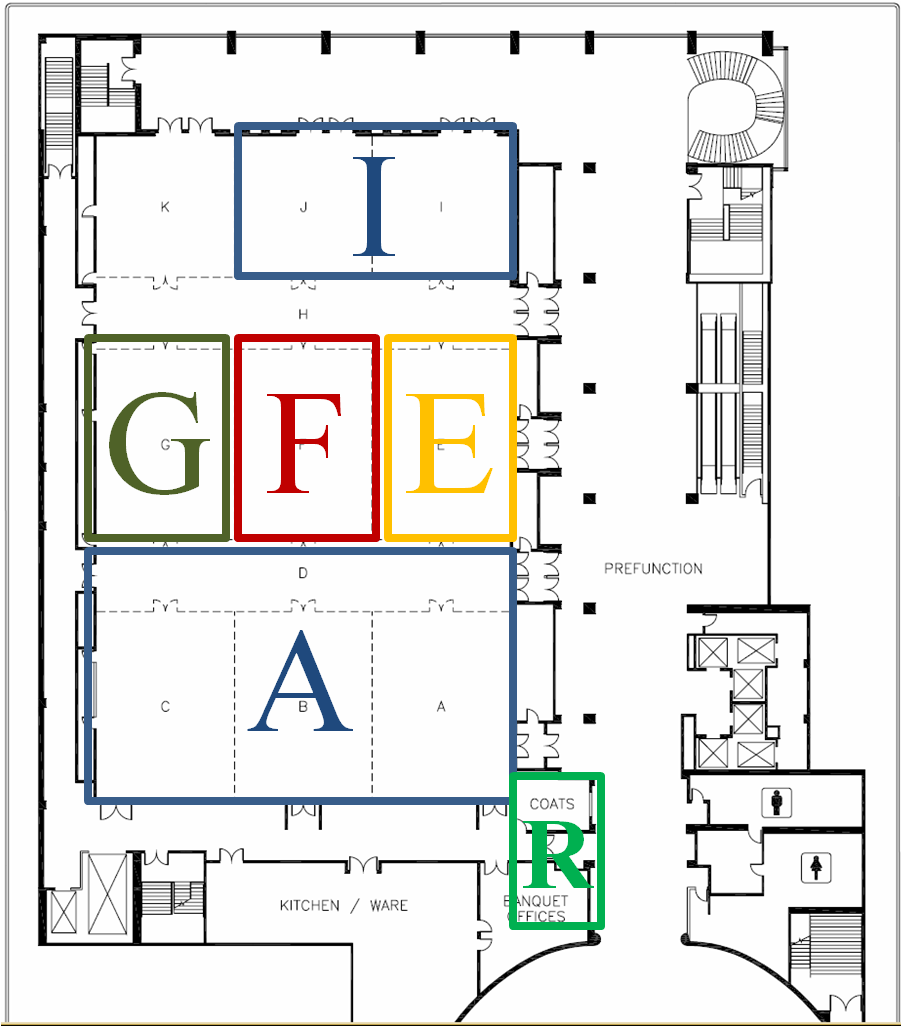
ICML 2011 has 5 parallel tracks denoted by letters.
The letter in the session identifier indicates the track.
The tracks map to sections of the ballroom as follows:
| Time | Session | Session Title
Session Chair | Paper Title | Authors |
| Wed, 8.30-9 | 1A | Welcome | Welcome address and Best Paper Awards | Zoubin Ghahramani, Lise Getoor, Tobias Scheffer |
| Wed, 9-10 | 1A | Keynote
John Platt | Embracing Uncertainty: Applied Machine Learning Comes of Age | Christopher Bishop |
| Wed, 10-10.30 | | Coffee Break | | |
| Wed, 10.30-12.10 | 2A | Bandits and Online Learning
John Langford | Unimodal Bandits | Jia Yuan Yu; Shie Mannor |
| | | On tracking portfolios with certainty equivalents on a generalization of Markowitz model: the Fool, the Wise and the Adaptive | Richard Nock; Brice Magdalou; Eric Briys; Frank Nielsen |
| | | Beat the Mean Bandit | Yisong Yue; Thorsten Joachims |
| | | Multiclass Classification with Bandit Feedback using Adaptive Regularization | Koby Crammer; Claudio Gentile |
| 2I | Structured Output
Mehryar Mohri | An Augmented Lagrangian Approach to Constrained MAP Inference | Andre Martins; Mario Figueiredo; Pedro Aguiar; Noah Smith; Eric Xing |
| | | Max-margin Learning for Lower Linear Envelope Potentials in Binary Markov Random Fields | Stephen Gould |
| | | Inference of Inversion Transduction Grammars | Alexander Clark |
| | | Minimal Loss Hashing for Compact Binary Codes | Mohammad Norouzi; David Fleet |
| 2E | Reinforcement Learning
Ron Parr | Structure Learning in Ergodic Factored MDPs without Knowledge of the Transition Function's In-Degree | Doran Chakraborty; Peter Stone |
| | | The Infinite Regionalized Policy Representation | Miao Liu; Xuejun Liao; Lawrence Carin |
| | | Online Discovery of Feature Dependencies | Alborz Geramifard; Finale Doshi; Joshua Redding; Nicholas Roy; Jonathan How |
| | | Doubly Robust Policy Evaluation and Learning | Miroslav Dudik; John Langford; Lihong Li |
| 2F | Graphical Models and Optimization
Nando de Freitas | Dynamic Tree Block Coordinate Ascent | Daniel Tarlow; Dhruv Batra; Pushmeet Kohli; Vladimir Kolmogorov |
| | | Approximation Bounds for Inference using Cooperative Cuts | Stefanie Jegelka; Jeff Bilmes |
| | | Convex Max-Product over Compact Sets for Protein Folding | Jian Peng; Tamir Hazan; David McAllester; Raquel Urtasun |
| | | On the Use of Variational Inference for Learning Discrete Graphical Models | Eunho Yang; Pradeep Ravikumar |
| 2G | Recommendation and Matrix Factorization
Dale Schuurmans | GoDec: Randomized Low-rank & Sparse Matrix Decomposition in Noisy Case | Tianyi Zhou; Dacheng Tao |
| | | Large-Scale Convex Minimization with a Low-Rank Constraint | Shai Shalev-Shwartz; Alon Gonen; Ohad Shamir |
| | | Linear Regression under Fixed-Rank Constraints: A Riemannian Approach | Gilles Meyer; Silvère Bonnabel; Rodolphe Sepulchre |
| | | Clustering by Left-Stochastic Matrix Factorization | Raman Arora; Maya Gupta; Amol Kapila; Maryam Fazel, |
| Wed, 12.10-1.40 | | Lunch Break | | |
| | MLJ Editorial Board Luncheon | | Machine Learning Journal |
| Wed, 1.40-3.20 | 3A | Neural Networks and Statistical Methods
Thore Graepel | Minimum Probability Flow Learning | Jascha Sohl-Dickstein; Peter Battaglino; Michael DeWeese |
| | | The Importance of Encoding Versus Training with Sparse Coding and Vector Quantization | Adam Coates; Andrew Ng |
| | | Learning Recurrent Neural Networks with Hessian-Free Optimization | James Martens; Ilya Sutskever |
| | | On Random Weights and Unsupervised Feature Learning | Andrew Saxe; Pang Wei Koh; Zhenghao Chen; Maneesh Bhand; Bipin Suresh; Andrew Ng |
| 3I | Latent-Variable Models
Alexander Ihler | On the Integration of Topic Modeling and Dictionary Learning | Lingbo Li; Mingyuan Zhou; Guillermo Sapiro; Lawrence Carin |
| | | Beam Search based MAP Estimates for the Indian Buffet Process | Piyush Rai; Hal Daume III |
| | | Tree-Structured Infinite Sparse Factor Model | XianXing Zhang; David Dunson; Lawrence Carin |
| | | Sparse Additive Generative Models of Text | Jacob Eisenstein; Amr Ahmed; Eric Xing |
| 3E | Large-Scale Learning
Rich Caruana | Hashing with Graphs | Wei Liu; Jun Wang; Sanjiv Kumar; Shih-Fu Chang |
| | | Large Scale Text Classification using Semi-supervised Multinomial Naive Bayes | Jiang Su; Jelber Sayyad Shirab; Stan Matwin |
| | | Parallel Coordinate Descent for L1-Regularized Loss Minimization | Joseph Bradley; Aapo Kyrola; Daniel Bickson; Carlos Guestrin |
| | | OptiML: An Implicitly Parallel Domain-Specific Language for Machine Learning | Arvind Sujeeth; HyoukJoong Lee; Kevin Brown; Tiark Rompf; Hassan Chafi; Michael Wu; Anand Atreya; Martin Odersky; Kunle Olukotun |
| 3F | Learning Theory
Sally Goldman | On the Necessity of Irrelevant Variables | Dave Helmbold; Phil Long |
| | | A PAC-Bayes Sample-compression Approach to Kernel Methods | Pascal Germain; Alexandre Lacoste; Francois Laviolette; Mario Marchand; Sara Shanian |
| | | Simultaneous Learning and Covering with Adversarial Noise | Andrew Guillory; Jeff Bilmes |
| | | Risk-Based Generalizations of f-divergences | Darío García-García; Ulrike von Luxburg; Raúl Santos-Rodríguez |
| 3G | Feature Selection, Dimensionality Reduction
Corinna Cortes | Eigenvalue Sensitive Feature Selection | Yi Jiang; Jiangtao Ren |
| | | Cauchy Graph Embedding | Dijun Luo; Chris Ding; Feiping Nie; Heng Huang |
| | | Tree preserving embedding | Albert Shieh; Tatsunori Hashimoto; Edo Airoldi |
| | | Stochastic Low-Rank Kernel Learning for Regression | Pierre Machart; Thomas Peel; Sandrine Anthoine; Liva Ralaivola; Hervé Glotin, |
| Wed, 3.20-3.50 | | Coffee Break | | |
| Wed, 3.50-5.30 | 4A | Invited Cross-Conference Track
Dragos Margineantu | Debt Collections Using Constrained Reinforcement Learning | Naoki Abe; Prem Melville; Cezar Pendus; David L. Jensen; Chandan K. Reddy; Vince P. Thomas; James J. Bennett; Gary F. Anderson; Brent R. Cooley; Melissa Weatherwax; Timothy Gardinier; Gerard Miller |
| | | Modeling Mutual Context of Object and Human Pose in Human-Object Interaction Activities | Bangpeng Yao; Aditya Khosla; Li Fei-Fei |
| | | Efficient Planning under Uncertainty for a Target-Tracking Micro-Aerial Vehicle in Urban Environments | Abraham Bachrach; Ruijie He; Nicholas Roy |
| | | Gesture-Based Human-Robot Jazz Improvisation | Gil Weinberg |
| 4I | Neural Networks and Deep Learning
Tomas Singliar | Learning attentional policies for tracking and recognition in video with deep networks | Loris Bazzani; Nando Freitas; Hugo Larochelle; Vittorio Murino; Jo-Anne Ting |
| | | Learning Deep Energy Models | Jiquan Ngiam; Zhenghao Chen; Pang Wei Koh; Andrew Ng |
| | | Unsupervised Models of Images by Spike-and-Slab RBMs | Aarron Courville; James Bergstra; Yoshua Bengio |
| | | On Autoencoders and Score Matching for Energy Based Models | Kevin Swersky; Marc'Aurelio Ranzato; David Buchman; Benjamin Marlin; Nando Freitas |
| 4E | Latent-Variable Models
Katherine Heller | Topic Modeling with Nonparametric Markov Tree | Haojun Chen; David Dunson; Lawrence Carin |
| | | Infinite SVM: a Dirichlet Process Mixture of Large-margin Kernel Machines | Jun Zhu; Ning Chen; Eric Xing |
| | | Piecewise Bounds for Estimating Bernoulli-Logistic Latent Gaussian Models | Benjamin Marlin*, University of British Columbia; Mohammad Khan, University of British Columbia; Kevin Murphy, University of British Columbia |
| | | A Spectral Algorithm for Latent Tree Graphical Models | Ankur Parikh; Le Song; Eric Xing |
| 4F | Active and Online Learning
Burr Settles | Speeding-Up Hoeffding-Based Regression Trees With Options | Elena Ikonomovska; João Gama; Bernard Zenko; Saso Dzeroski |
| | | Adaptively Learning the Crowd Kernel | Omer Tamuz; Ce Liu; Serge Belongie; Ohad Shamir; Adam Kalai |
| | | Bundle Selling by Online Estimation of Valuation Functions | Daniel Vainsencher; Ofer Dekel; Shie Mannor |
| | | Active Learning from Crowds | Yan Yan; Romer Rosales; Glenn Fung; Jennifer Dy |
| 4G | Ensemble Methods
Chris Burges | Efficient Rule Ensemble Learning using Hierarchical Kernels | Pratik Jawanpuria; Saketha Nath Jagarlapudi; Ganesh Ramakrishnan |
| | | Boosting on a Budget: Sampling for Feature-Efficient Prediction | Lev Reyzin |
| | | Multiclass Boosting with Hinge Loss based on Output Coding | Tianshi Gao; Daphne Koller |
| | | Generalized Boosting Algorithms for Convex Optimization | Alexander Grubb; Drew Bagnell |
| Wed, 5.30-6 | 5A | Test-of-Time
Tom Dietterich | Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data | John D. Lafferty; Andrew McCallum; Fernando C. N. Pereira |
| Wed, 6-10 | Evg | Poster Session | Papers from Sessions 2A-7G - Evergreen Balroom | |
| Time | Session | Session Title
Session Chair | Paper Title | Authors |
| Fri, 8.30-9.30 | 10A | Keynote
Tobias Scheffer | Machine Learning in Google Goggles | Hartmut Neven |
| Fri, 9.30-10 | | Coffee Break | | |
| Fri, 10-12.10 | 11A | Graphical Models and Bayesian Inference
Pradeep Ravikumar | Variational Heteroscedastic Gaussian Process Regression | Miguel Lazaro-Gredilla; Michalis Titsias |
| | | Predicting Legislative Roll Calls from Text | Sean Gerrish; David Blei |
| | | Bounding the Partition Function using Holder's Inequality | Qiang Liu; Alexander Ihler |
| | | On Bayesian PCA: Automatic Dimensionality Selection and Analytic Solution | Shinichi Nakajima; Masashi Sugiyama; Derin Babacan |
| | | Bayesian CCA via Group Sparsity | Seppo Virtanen; Arto Klami; Samuel Kaski |
| 11I | Sparsity and Compressed Sensing
Nati Srebro | Efficient Sparse Modeling with Automatic Feature Grouping | Wenliang Zhong; James Kwok |
| | | Robust Matrix Completion and Corrupted Columns | Yudong Chen; Huan Xu; Constantine Caramanis; Sujay Sanghavi |
| | | Clustering Partially Observed Graphs via Convex Optimization | Ali Jalali; Yudong Chen; Sujay Sanghavi; Huan Xu |
| | | Noisy matrix decomposition via convex relaxation: Optimal rates in high dimensions | Alekh Agarwal; Sahand Negahban; Martin Wainwright |
| | | Submodular meets Spectral: Greedy Algorithms for Subset Selection, Sparse Approximation and Dictionary Selection | Abhimanyu Das; David Kempe |
| 11E | Clustering
Jennifer Neville | On Information-Maximization Clustering: Tuning Parameter Selection and Analytic Solution | Masashi Sugiyama; Makoto Yamada; Manabu Kimura; Hirotaka Hachiya |
| | | Pruning nearest neighbor cluster trees | Samory Kpotufe; Ulrike von Luxburg |
| | | A Co-training Approach for Multi-view Spectral Clustering | Abhishek Kumar; Hal Daume III |
| | | Clusterpath: an Algorithm for Clustering using Convex Fusion Penalties | Toby Hocking; Jean-Philippe Vert; Francis Bach; Armand Joulin |
| | | A Unified Probabilistic Model for Global and Local Unsupervised Feature Selection | Yue Guan; Jennifer Dy; Michael Jordan |
| 11F | Game Theory and Planning and Control
Shie Mannor | Integrating Partial Model Knowledge in Model Free RL Algorithms | Aviv Tamar; Dotan Di Castro; Ron Meir |
| | | Task Space Retrieval Using Inverse Feedback Control | Nikolay Jetchev; Marc Toussaint |
| | | PILCO: A Model-Based and Data-Efficient Approach to Policy Search | Marc Deisenroth; Carl Rasmussen |
| | | Approximating Correlated Equilibria using Relaxations on the Marginal Polytope | Hetunandan Kamisetty; Eric Xing; Christopher Langmead |
| | | Generalized Value Functions for Large Action Sets | Jason Pazis; Ron Parr |
| 11G | Semi-Supervised Learning
William Cohen | Vector-valued Manifold Regularization | Ha Quang Minh; Vikas Sindhwani |
| | | Semi-supervised Penalized Output Kernel Regression for Link Prediction | Céline Brouard; Florence D'Alche-Buc; Marie Szafranski |
| | | Access to Unlabeled Data can Speed up Prediction Time | Ruth Urner; Shai Shalev-Shwartz; Shai Ben-David |
| | | Automatic Feature Decomposition for Single View Co-training | Minmin Chen; Kilian Weinberger; Yixin Chen |
| | | Towards Making Unlabeled Data Never Hurt | Yu-Feng Li; Zhi-Hua Zhou |
| Fri, 12.10-1.40 | | Lunch Break | | |
| | IMLS Board Luncheon | | IMLS Board Members |
| Fri, 1.40-3.45 | 12A | Kernel Methods and Optimization
Thorsten Joachims | Learning Output Kernels with Block Coordinate Descent | Francesco Dinuzzo; Cheng Soon Ong; Peter Gehler; Gianluigi Pillonetto |
| | | Implementing regularization implicitly via approximate eigenvector computation | Michael Mahoney; Lorenzo Orecchia |
| | | Adaptive Kernel Approximation for Large-Scale Non-Linear SVM Prediction | Michele Cossalter; Rong Yan; Lu Zheng |
| | | Suboptimal Solution Path Algorithm for Support Vector Machine | Masayuki Karasuyama; Ichiro Takeuchi |
| | | Functional Regularized Least Squares Classication with Operator-valued Kernels | Hachem Kadri; Asma Rabaoui; Philippe Preux; Emmanuel Duflos; Alain Rakotomamonjy |
| 12I | Neural Networks and NLP
Hal Daume III | Parsing Natural Scenes and Natural Language with Recursive Neural Networks | Richard Socher; Cliff Chiung-Yu Lin; Andrew Ng; Chris Manning |
| | | Domain Adaptation for Large-Scale Sentiment Classification: A Deep Learning Approach | Xavier Glorot; Antoine Bordes; Yoshua Bengio |
| | | Large-Scale Learning of Embeddings with Reconstruction Sampling | Yann Dauphin; Xavier Glorot; Yoshua Bengio |
| | | Generating Text with Recurrent Neural Networks | Ilya Sutskever; James Martens; Geoffrey Hinton |
| | | Contractive Auto-Encoders: Explicit Invariance During Feature Extraction | Salah Rifai; Pascal Vincent; Xavier Muller; Xavier Glorot; Yoshua Bengio |
| 12E | Probabilistic Models & MCMC
Ruslan Salakhutdinov | Probabilistic Matrix Addition | Amrudin Agovic; Arindam Banerjee; Snigdhansu Chatterje |
| | | SampleRank: Training Factor Graphs with Atomic Gradients | Michael Wick; Khashayar Rohanimanesh; Kedar Bellare; Aron Culotta; Andrew McCallum |
| | | A New Bayesian Rating System for Team Competitions | Sergey Nikolenko; Alexander Sirotkin |
| | | Bayesian Learning via Stochastic Gradient Langevin Dynamics | Max Welling; Yee Whye Teh |
| | | ABC-EP: Expectation Propagation for Likelihood-free Bayesian Computation | Simon Barthelmé; Nicolas Chopin |
| 12F | Online Learning
Claudio Gentile | Online AUC Maximization | Peilin Zhao; Steven Hoi; Rong Jin; Tianbao Yang |
| | | Online Submodular Minimization for Combinatorial Structures | Stefanie Jegelka; Jeff Bilmes |
| | | Better Algorithms for Selective Sampling | Francesco Orabona; Nicolò Cesa-Bianchi |
| | | Learning Linear Functions with Quadratic and Linear Multiplicative Updates | Tom Bylander |
| | | Optimal Distributed Online Prediction | Ofer Dekel; Ran Gilad-Bachrach; Ohad Shamir; Lin Xiao |
| 12G | Ranking and Information Retrieval
Mikhail Bilenko | Learning Mallows Models with Pairwise Preferences | Tyler Lu; Craig Boutilier |
| | | Preserving Personalized Pagerank in Subgraphs | Andrea Vattani; Deepayan Chakrabarti; Maxim Gurevich |
| | | Learning Scoring Functions with Order-Preserving Losses and Standardized Supervision | David Buffoni; Clément Calauzenes; Patrick Gallinari; Nicolas Usunier |
| | | Bipartite Ranking through Minimization of Univariate Loss | Wojciech Kotlowski; Krzysztof Dembczynski; Eyke Huellermeier |
| | | k-DPPs: Fixed-Size Determinantal Point Processes | Alex Kulesza; Ben Taskar |
| Fri, 3.45-4.15 | | Coffee break | | |
| Fri, 4.15-5.15 | 13A | Keynote
Ray Mooney | Building Watson: An Overview of the DeepQA Project | David Ferrucci |
| Fri, 5.15-6.15 | 14A | Business Meeting
Ray Mooney | | Lise Getoor, Tobias Scheffer |
| Fri, 6-10 | | Poster Session | Papers from Sessions 8A-12G - Evergreen Balroom | |

![[Twitter]](http://twitter-badges.s3.amazonaws.com/t_small-a.png)
![[FB]](img/fbicon.gif)