From Dirichlet to Rubin: Optimistic Exploration in RL without Bonuses
Daniil Tiapkin · Denis Belomestny · Eric Moulines · Alexey Naumov · Sergey Samsonov · Yunhao Tang · Michal Valko · Pierre Menard
2022 Poster
{kind=link}
Abstract
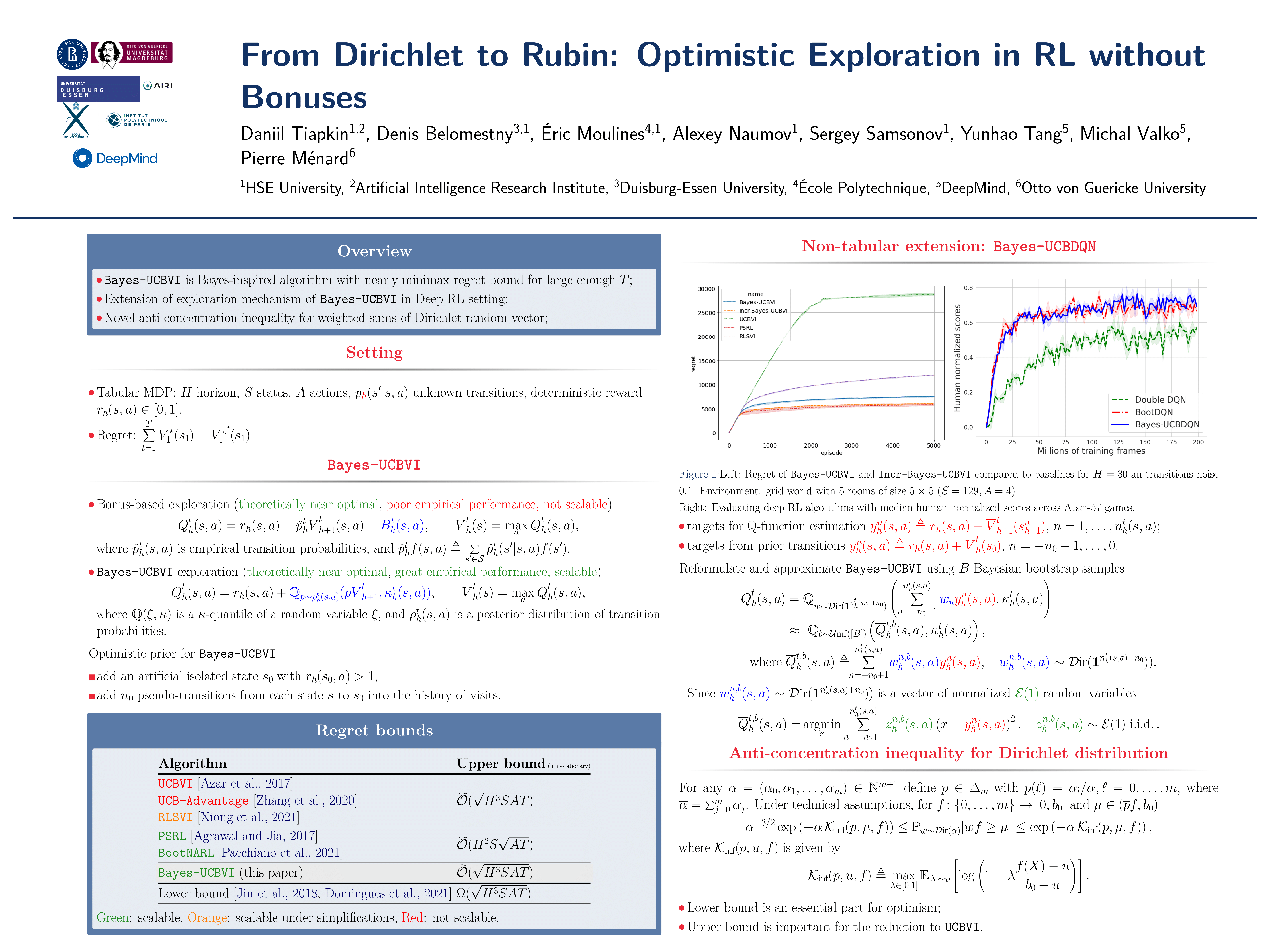
We propose the Bayes-UCBVI algorithm for reinforcement learning in tabular, stage-dependent, episodic Markov decision process: a natural extension of the Bayes-UCB algorithm by Kaufmann et al. 2012 for multi-armed bandits. Our method uses the quantile of a Q-value function posterior as upper confidence bound on the optimal Q-value function. For Bayes-UCBVI, we prove a regret bound of order $\widetilde{\mathcal{O}}(\sqrt{H^3SAT})$ where $H$ is the length of one episode, $S$ is the number of states, $A$ the number of actions, $T$ the number of episodes, that matches the lower-bound of $\Omega(\sqrt{H^3SAT})$ up to poly-$\log$ terms in $H,S,A,T$ for a large enough $T$. To the best of our knowledge, this is the first algorithm that obtains an optimal dependence on the horizon $H$ (and $S$) \textit{without the need of an involved Bernstein-like bonus or noise.} Crucial to our analysis is a new fine-grained anti-concentration bound for a weighted Dirichlet sum that can be of independent interest. We then explain how Bayes-UCBVI can be easily extended beyond the tabular setting, exhibiting a strong link between our algorithm and Bayesian bootstrap (Rubin,1981).
Chat is not available.
Successful Page Load